
![]()
Caché’s high-performance database uses a multidimensional data engine that allows efficient and compact storage of data in a rich data structure. Objects and SQL are implemented by specifying a unified data dictionary that defines the classes and tables and provides a mapping to the multidi-mensional structures – a mapping that can be automatically generated.
Caché gives programmers the freedom to store and access data through objects, SQL, or direct access to multidimensional structures. Regardless of the access method, all data in Caché’s data-base is stored in Caché’s multidimensional arrays.
Once the data is stored, all three access methods can be simultaneously used on the same data with full concurrency.
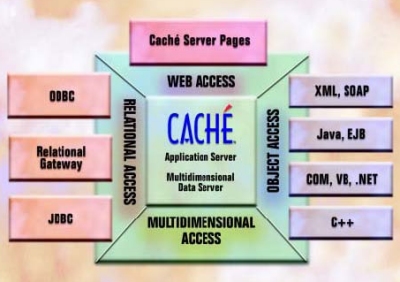
A unique feature of Caché is its Unified Data Architecture. Whenever a database object class is defined, Caché automati-cally generates an SQL-ready relational description of that data. Similarly, if a DDL description of a relational database is imported into the Data Dictionary, Caché automatically gener-ates both a relational and an object description of the data, enabling immediate access as objects. Caché keeps these descriptions coordinated; there is only one data definition to edit. The programmer can edit and view the dictionary both from an object and a relational table perspective.
Caché automatically creates a mapping for how the objects and tables are stored in the multidimensional structures, or the programmer can explicitly control the mapping.
The Caché AdvantageFlexibility Caché’s data access modes – Object, SQL, and Direct – can be used concurrently on the same data. This flexibility gives programmers the freedom to think about data in the way that makes most sense and to use the access method that best fits each program’s needs. Less Work Caché’s Unified Data Architecture automatically describes data as both objects and tables with a single definition. There is no need to code transformations, so applications can be developed and maintained more easily. Leverage Existing Skills and Applications Programmers can leverage existing relational skills and introduce object capabilities gradually into existing applications as they evolve. |
At its core, the Caché database is powered by an extremely efficient multidimensional data engine. Direct access to multidimensional structures is provided by built-in Caché scripting languages – providing the highest performance and greatest range of storage possibilities – and many applica-tions are implemented entirely using this data engine directly. Direct “global access” is particularly common when there are unusual or very specialized structures and no need to provide object or SQL access to them, or where the highest possible performance is required.
There is no data dictionary, and thus no data definitions, for the multidimensional data engine.
Rich Multidimensional Data Structure
Caché’s multidimensional arrays are called “globals”. Data can be stored in a global with any number of subscripts. What’s more, subscripts are typeless and can hold any sort of data. One subscript might be an integer, such as 34, while another could be a meaningful name, like “LineItems”– even at the same subscript level.
For example, a stock inventory application that provides information about item, size, color, and pattern might have a structure like this:
^Stock(item,size,color,pattern) = quantity
Here’s some sample data:
^Stock(”slip dress”,4,”blue”,”floral”)=3
With this structure it is very easy to determine if there are any size 4 blue slip dresses with a floral pattern – simply by accessing that data node. If a customer wants a size 4 slip dress and is uncertain about color and pattern, it is easy to display a list of all of those by cycling through all of the data nodes below
^Stock(”slip dress”,4)
In this example all of the data nodes were of a similar nature (they stored a quantity), and they were all stored at the same subscript level (4 subscripts) with similar subscripts (the 3rd subscript was always text representing a color). However, they don’t have to be. Not all data nodes have to have the same number or type of subscripts, and they may contain different types of data.
Here’s an example of a more complex global with invoice data that has different types of data stored at different subscript levels:
^Invoice(invoice #,”Customer”) = Customer information
^Invoice(invoice #,”Date”) = Invoice date
^Invoice(invoice #,”Items”) = # of Items in the invoice
^Invoice(invoice #,”Items”,1,”Part”) = part number of 1st Item
^Invoice(invoice #,”Items”,1,”Quantity”) = quantity of 1st Item
^Invoice(invoice #,”Items”,1,”Price”) = price of 1st Item
^Invoice(invoice #,”Items”,2,”Part”) = part number of 2nd Item
etc.
Multiple Data Elements per Node
 Often
only a single data element is stored in a data node, such as a date or quantity,
but sometimes it is useful to store multiple data elements together in a single
data node. This is particularly useful when there is a set of related data that
is often accessed together. It can also improve performance by requiring fewer
accesses of the database.
Often
only a single data element is stored in a data node, such as a date or quantity,
but sometimes it is useful to store multiple data elements together in a single
data node. This is particularly useful when there is a set of related data that
is often accessed together. It can also improve performance by requiring fewer
accesses of the database.
For example, in the above invoice each item included a part number, quantity, and price all stored as separate nodes, but they could be stored as a list of elements in a single node:
^Invoice(invoice #,”LineItems”,item #)
To make this simple, Caché supports a function called $list() which can assemble multiple data elements into a length delimited byte string and later disassemble them, preserving datatype.
Logical Locking Promotes High Concurrency
In systems with thousands of users, reducing conflicts between competing processes is critical to providing high throughput. One of the biggest conflicts is between transactions wishing to access the same data.
Caché processes don’t lock entire pages of data while performing updates. Instead, because transactions require frequent access or changes to small quantities of data, database locking in Caché is done at a logical level. Database conflicts are further reduced by using atomic addition and subtraction operations, which don’t require locking. (These operations are particularly useful in incrementing counters used to allocate ID numbers and for modifying statistics counters.)
With Caché, individual transactions run faster, and more transactions can run concurrently.
Variable Length Data in Sparse Arrays
Because Caché data is inherently variable length and is stored in sparse arrays, Caché often requires less than one half of the space needed by a relational database. In addition to reducing disk requirements, compact data storage enhances performance because more data can be read or written with a single I/O operation, and data can be cached more efficiently.
Declarations and Definitions Aren’t Required
Caché multidimensional arrays are inherently typeless, both in their data and subscripts. No declarations, definitions, or allocations of storage are required. Global data simply pops into existence as data is inserted.
Namespaces
In Caché, data and code are stored in disk files with the name CACHE.DAT (only one per directory). Each such file contains numerous “globals” (multidimensional arrays). Within a file, each global name must be unique, but different files may contain the same global name. These files may be loosely thought of as databases.
Rather than specifying which database file to use, each Caché process uses a “namespace” to access data. A namespace is a logical map that maps the names of multidimensional global arrays and code to databases. If a database is moved from one disk drive or computer to another, only the namespace map needs to be updated. The application itself is unchanged.
Usually, other than some system information, all data for a namespace is stored in a single database. However, namespaces provide a flexible structure that allows arbitrary mapping, and it is not unusual for a namespace to map the contents of several databases, including some on other computers.
The Caché AdvantagePerformance By using an efficient multidimensional data model with sparse storage techniques instead of a cumbersome maze of two-dimensional tables, data access and updates are accomplished with less disk I/O. Reduced I/O means that applications will run faster. Scalability The transactional multidimensional data model allows Caché-based applications to be scaled to many thousands of clients without sacrificing high performance. That’s because data access in a multidimensional model is not significantly affected by the size or complexity of the database in comparison to relational models. Transactions can access the data they need without performing complicated joins or bouncing from table to table. Caché’s use of logical locking for updates instead of locking physical pages is another important contributor to concurrency, as is its sophisticated data caching across networks. Rapid Development With Caché, development occurs much faster because the data structure provides natural, easily understood storage of complex data and doesn’t require extensive or complicated declarations and definitions. Direct access to globals is very simple, allowing the same language syntax as accessing local arrays. Cost-Effectiveness Compared to comparably sized relational applications, Caché-based applications require significantly less hardware and no database administrators. System management and operations are simple.
|
SQL is the query language for Caché, and it supports a full set of relational database capabilities – including DDL, transactions, referential integrity, triggers, stored procedures, and more. Caché supports access through ODBC and JDBC (using a pure Java-based driver). SQL commands and queries can also be embedded in Caché ObjectScript and within object methods.
SQL accesses data viewed as tables with rows and columns. Because Caché data is actually stored in efficient multidimensional structures, applications that use SQL achieve better performance with Caché than when they run against traditional relational databases. The performance is apparent both with highly efficient compiled queries, as well as with the execution of dynamic (defined at run time) SQL statements.
Caché supports, in addition to the standard SQL syntax, many of the commonly used extensions in other databases so that many SQL-based applications can run on Caché without change – especially those written with database independent tools. However, vendor-specific stored procedures will require some work, and InterSystems has translators to help with that work.
Caché SQL includes object enhancements that make SQL code simpler and more intuitive to read and write.
|
Traditional SQL
|
Object Extended SQL
|
Accessing Relational Databases with Caché Relational Gateway
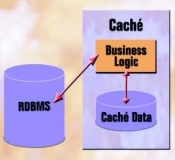 |
The Caché Relational Gateway enables an SQL request that originates in Caché to be sent to other (relational) databases for processing. Using the Gateway, a Caché application can retrieve and update data stored in most relational databases.
Additionally, if Caché database classes are compiled using the CachéSQLStorage
option, the Gateway allows Caché applications to transparently use relational
data-bases. However, applications will run faster and be more scalable if they
access Caché’s post-relational database.
The Caché AdvantageFaster SQL Relational applications can enjoy significantly enhanced performance by using Caché SQL to tap into Caché’s efficient post-relational database. Faster Development In Caché, SQL queries can be written more intuitively, using fewer lines of code. Compatibility With Existing Applications and Report Writers Caché’s native ODBC and JDBC drivers provide high performance interoperability with conventional applications, including most popular data analysis and reporting tools.
|
Caché’s object model is based upon the ODMG standard. Caché supports a full array of object programming concepts including encapsulation, embedded objects, multiple inheritance, polymorphism, and collections.
The built-in Caché scripting languages directly manipulate these objects, and Caché also exposes Caché classes as Java, EJB, COM, .NET, and C++ classes. Caché classes can also be automatically enabled for XML and SOAP support by simply clicking a button in the Studio IDE. As a result, Caché objects are readily available to every commonly used object technology.
State for Caché objects is always maintained in the Caché Application Server. When a Java, C++, C#, Visual Basic, or other program outside of the Application Server accesses a Caché object, it calls a template of the class in the native language. That template class (which is automatically generated by Caché) communicates with the Caché Application Server to invoke methods on the Caché server and to access or modify properties. To speed execution and reduce messaging, Caché caches a copy of the object’s data on the client and piggy-backs updates with other messages when possible. To the user program, it looks like the object is local; Caché transparently handles all communications with the server.
The Java template and supporting library is completely Java-based, so it can be used across the Web or on specialized Java devices.
Method Generators
Caché includes a number of unique advanced object technologies – one of which is method genera-tors. A method generator is a method that executes at compile time, generating code that can run when the program is executed. A method generator has access to class definitions, including prop-erty and method definitions and parameters, to allow it to generate a method that is customized for the class. Method generators are particularly powerful in combination with multiple inheritance – functionality can be defined in a multiply inherited class that customizes itself to the subclass.
The Caché AdvantageCaché is fully object-enabled, providing all the power of object technology to developers of high-performance transaction processing applications. Rapid Application Development Object technology is a powerful tool for increasing programmer productivity. Developers can think about and use objects – even extremely complex objects – in simple and realistic ways, thus speeding the application development process. Also, the innate modularity and interoperability of objects simplifies application maintenance, and lets programmers leverage their work over many projects. |
Caché uniquely provides Transactional Bit-Map Indexing, which can radically increase performance of complex queries giving fast data warehouse query performance on live data.
Database performance is critically dependent on having indexes on properties that are frequently used in searching the database. Most databases use indexes that, for each possible value of the column or property, maintain a list of the row IDs (or object IDs) for the rows/objects that have that value.
A bit-map index is another type of index. Bit-map indexes contain a separate bitmap for each possible value of a column/property, with one bit for each row/ object that is stored. A 1 bit means that the row/object has that value for the column/property.
The advantage of bit-map indexes is that complex queries can be processed by performing Boolean operations (AND, OR) on the indexes – efficiently determin-ing exactly which instances (rows) fit the query conditions, without searching through the entire database. Bit-map indexes can often boost response times for queries that search large volumes of data by a factor of 100 or more.
Bit-maps traditionally suffer from two problems: a) they can be painfully slow to update in relational databases, and b) they can take up far too much storage. Thus with relational databases, they are rarely used for transaction processing applications.
Caché has introduced a new technology – “transactional bit-map indexes” – that leverages multidimensional data structures to eliminate these two problems. Updating these bit-maps is often faster than traditional indexes, and they utilize sophisticated compression techniques to radically reduce storage. The result is ultra fast bit-maps that can often be used to search millions of records in a fraction of a second on an on-line transaction-processing database. Business intelligence and data warehousing applications can work with “live” data.
Caché offers both traditional and transactional bit-map indexes. Caché also supports multi-column indexes. For example, an index on State and CarModel, can quickly identify everyone who has a car of a particular type that is registered in a particular state.
The Caché AdvantageRadically Faster Queries By using transactional bit-map techniques, users can get blazing fast searches of large databases – often millions of records can be searched in a fraction of a second – on a system that is primarily used for transac-tion processing. Real-Time Data Analytics Caché’s Transactional Bit-Map Indexing allows real-time data analytics on up-to-the-minute data. Lower Cost There is no need for a second computer dedicated to data warehouse and decision support. Nor is there any need for daily operations to transfer data to such a second system or database administrators to support it. Scalability The speed of transac-tional bit-maps enhances the ability to build systems with enormous amounts of data that need to be maintained and periodically searched. |
Scalable Performance in Distributed Systems
InterSystems’ Enterprise Cache Protocol (ECP) is an extremely high performance and scalable technology that enables computers in a distributed system to use each other’s databases. The use of ECP requires no application changes – applications simply treat the database as if it was local.
Here’s how ECP works. Each Application Server includes its own Data Server, which can operate on data that resides in its own disk systems or on blocks that were transferred to it from another Data Server by ECP. When a client makes a request for information, the Caché Application Server will attempt to satisfy the request from its local cache. If it cannot, it will request the necessary data from the remote Caché Data Server. The reply includes the database block(s) where that data was stored. These blocks are cached on the Application Server, where they are available to all applica-tions running on that server. ECP automatically takes care of managing cache consistency across the network and propagating changes back to Data Servers.
The performance and scalability benefits of ECP are dramatic. Clients enjoy fast responses because they frequently use locally cached data. And caching greatly reduces network traffic between the database and application servers, so any given network can support many more servers and clients.
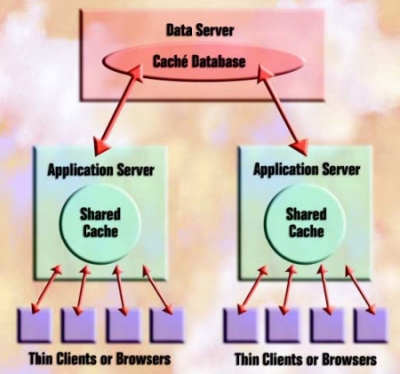
Easy to Use – No Application Changes
The use of ECP is transparent to applications. Applications written to run on a single server run in a multi-server environment without change. To use ECP, the system manager simply identifies one or more Data Servers to an Application Server and then uses Namespace Mapping to indicate that references to some or all global structures (or portions of global structures) refer to that remote Data Server.
Configuration Flexibility
Every Caché system can function both as an Application Server and as a Data Server for other systems. ECP supports any combination of Application Servers and Data Servers and any point-to-point topology of up to 255 systems.
For distributed systems using Enterprise Cache Protocol, upon a temporary network outage or a Data Server crash and reboot, the servers attempt to recon-nect. If a successful reconnect occurs within a specified time period, the Applica-tion Servers resend any uncompleted requests, and operations continue with no observable effect to users of the remote Application Servers other than a slight pause. Otherwise open transactions are rolled back, and user processes are issued an error.
In some configurations, a Data Server can also be configured to fail-over to a Shadow Server or cluster member, further enhancing reliability. The new Server resumes processing for the failed Data Server, allowing uninterrupted operation.
Clusters
Database Clusters support automatic fail-over features. In a Database Cluster, multiple computers access the same disk drives and use cluster capabilities to coordinate shared or exclusive access to disk blocks. If one computer fails, its processes are lost but the other computers continue to function. The failed computer’s users have their in-progress transactions rolled back, and those users may then sign onto another computer. Often load balancing is used in assigning users dynamically to clustered computers.
Although Database Clusters provide operational flexibility and enhanced reliability, they usually require more system management than other systems, and they require special hardware and operating system support.
Shadow Servers
Each Data Server can have a backup server – called a Shadow Server – that constantly reads the journal of the main server and updates the backup server’s database.
In the event that the connection between the servers is temporarily broken, the Shadow Server catches up when the connection is restored.
The Caché AdvantageMassive Scalability Caché’s Enterprise Cache Protocol allows the addition of application servers as usage grows, each of which uses the database as if it was a local database. If disk throughput becomes a bottleneck, more Data Servers can be added, and the database becomes logically partitioned. Higher Availability Because users are spread across multiple computers, the failure of an Application Server affects a smaller population. Should a Data Server “crash” and be re-booted, or there is a temporary network outage, the Application Servers can continue processing with no observable affects other than a slight pause. In some configura-tions, a Data Server can also be configured to fail-over to a Shadow Server or clustered system, further enhancing reliability. Lower Costs Large numbers of lost-cost computers can be combined into an extremely powerful system supporting massive processing — “grid computing”. Transparent Usage Applications don’t need to be written specifi-cally for ECP — Caché applications can automatically take advantage of ECP without change. |
 Caché
is designed to run 24 hours a day, every day of the year, on systems ranging
from small 4-user systems to systems with tens of thousands of users. Many Caché
installations are performed by Application Partners, who often have a need to
install large systems but can’t afford to provide on-going extensive system
management support. These requirements place great demands on the needs for
simplicity while supporting the sophisti-cated needs of large sites.
Caché
is designed to run 24 hours a day, every day of the year, on systems ranging
from small 4-user systems to systems with tens of thousands of users. Many Caché
installations are performed by Application Partners, who often have a need to
install large systems but can’t afford to provide on-going extensive system
management support. These requirements place great demands on the needs for
simplicity while supporting the sophisti-cated needs of large sites.
In Caché there is no need to perform operations such as periodically rebuilding indexes for performance or reloading a database when a new version is released, as is common with some relational systems. Such operations are neither simple nor conducive to 24-hour operation. Caché includes a full complement of system management utilities, all of which can be accessed remotely. Major system management functions can be scripted for unattended operation.
Unattended Backup While the Database is Being Updated
Caché supports full, incremental, and cumulative incremental backups. These backups can be performed while the database is up and running, including while database updates are occurring. Backups can be scripted so they are performed automatically without an operator.
Hardware and Database Reconfigurations Without Downtime
On each system, Caché maintains “namespace maps” that specify where data and code is stored. Changes to the system, even major changes such as adding a database server or switching to a backup server, can be accomplished by revising the namespace map. Scheduled reconfigurations can be done dynamically, without down time, in a manner transparent to applications. Contin-gency Namespace Maps can be configured to compensate for a variety of failure scenarios.
Introducing Source Changes on a Running System
It is not always practical to halt operations to introduce code changes, and with thousands of PCs and multiple servers, introducing changes can be a real problem.
Caché simplifies this process. To introduce a change in Caché ObjectScript or Basic into a running system, simply load the changed source routine onto the single Data Server where the code resides. The code will be automatically compiled – no linking is required – and Application Servers will be notified they need to reload the revised routine. Of course, such changes should be introduced with caution; a process that made a call from the old version to another routine will get an error upon attempting to return to the changed routine.
The Caché AdvantageSimplified System Management Caché is designed to make day-to-day system management easy by automating required tasks (such as backups) and eliminating many administrative tasks common in other databases. Less system management translates into less trouble and lower costs. No DBA Caché is so easy to manage, most installations do not even have a DBA. Dynamic Reconfiguration Dynamic namespace mapping allows system reconfiguration to be accomplished “on the fly”, without interrupting application availability. Robust 24-Hour Operation On-line backup, Shadow Servers, and Database Clusters support 24-hour operation and seamless recovery from failures. |
Caché Technology Guide